
前言
最近在搞华为组织的野鸡软件精英挑战赛,虽然成绩不忍直视,可在学长的经验分享中提到了OpenMP,刚好之前也了解到一本好书《OpenMP核心技术指南》,便乘初赛的在线训练到正式赛这段空段读了一读。对于这本书,我的感受还是易于理解的,而且整体知识难度较低,而如果你只想飞速上手的话,只要阅读第9章就可以了。
OpenMP这东西确实精妙,使得串行的程序加上几行#pragma omp就可以变得并行,比什么pthread,std::thread高到不知道哪里去了。
OpenMP优化自适应Simpson积分
我通过一个求一个$\int_1^{10^7}\frac{\sin x}{x}\mathrm{d}x \approx 0.624713$的自适应Simpson积分来巩固我的学习成果(虽然只用了task,但我认为是一个非常有用的运用)
//Author:rabbyte
#include <stdio.h>
#include <math.h>
#include <omp.h>
const double eps = 1e-16; //为了延长测试时间,精度设的比较高
double L = 1.0, R = 1e7, start_time, end_time;
inline double f(double x) {return sin(x) / x;}
inline double F(double l, double r) {return (r - l) * (f(l) + 4 * f((l + r) / 2) + f(r)) / 6;}
double Simpson(double L, double R) {
double mid = (L + R) / 2;
double ans = F(L, R), fl = F(L, mid), fr = F(mid, R);
if (fabs(fl + fr - ans) < eps) return ans;
fl = Simpson(L, mid); fr = Simpson(mid, R);
return fl + fr;
}
double Parallel_Simpson(double L, double R) {
double mid = (L + R) / 2;
double ans = F(L, R), fl = F(L, mid), fr = F(mid, R);
if (fabs(fl + fr - ans) < eps) return ans;
if (R - L > 1e5) { // 控制Task个数,如果没有则会造成史诗级负优化
#pragma omp task shared(fl)
fl = Parallel_Simpson(L, mid);
#pragma omp task shared(fr)
fr = Parallel_Simpson(mid, R);
#pragma omp taskwait
}
else {
fl = Parallel_Simpson(L, mid);
fr = Parallel_Simpson(mid, R);
}
return fl + fr;
}
int main() {
start_time = omp_get_wtime();
printf("Serial Ans : %f\n", Simpson(L, R));
end_time = omp_get_wtime();
printf("Serial Time : %f s\n", end_time - start_time);
start_time = omp_get_wtime();
#pragma omp parallel
{
#pragma omp single
printf("Parallel Ans : %f\n", Parallel_Simpson(L, R));
}
end_time = omp_get_wtime();
printf("Parallel Time : %f s\n", end_time - start_time);
return 0;
}
运行结果
编译环境:gcc version 11.2.0 MinGW-W64 x86_64-posix-seh 编译参数:
gcc -O3 -fopenmp simpson.c -o simpson
我的 Surface Book 2(15inch) (4Cores)
Serial Ans : 0.624713
Serial Time : 90.171000 s
Parallel Ans : 0.624713
Parallel Time : 22.680000 s
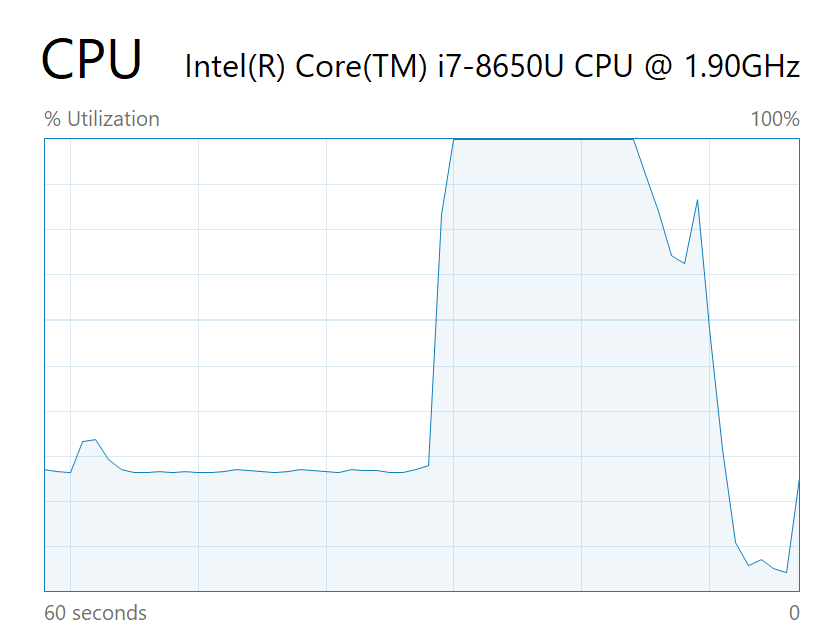 PS: 跑的时候睿频到3.2GHz左右,所以单核才和下面的差不多
PS: 跑的时候睿频到3.2GHz左右,所以单核才和下面的差不多
舍友的小新Pro14 (8Cores)
Serial Ans : 0.624713
Serial Time : 86.433000 s
Parallel Ans : 0.624713
Parallel Time : 10.644000 s
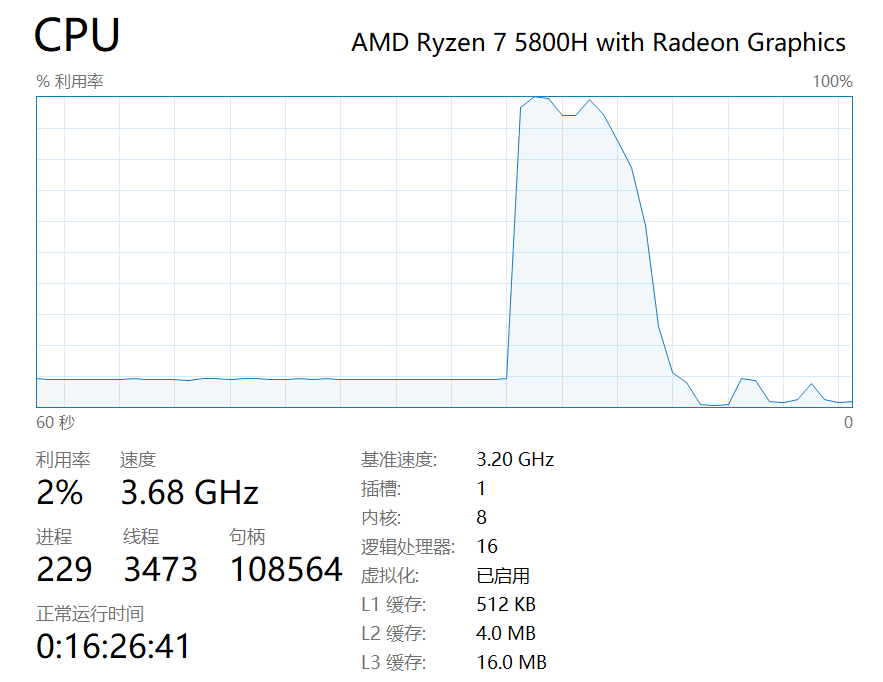
总结
根据上面两张图和运行时间可以看出OpenMP对于这个程序的优化大概就是CPU核数分之一,甚至还不止(估计是因为缓存的连续性)。而且在多核测试中基本能跑满,整体程序上改动很小,最棒的是编译器级别的支持,可以说是一件神器了。可惜的是算法竞赛不允许添加编译参数。